万字长文带你梳理Llama开源家族:从Llama-1到Llama-3
社区是国内外知名的机器学习与自然语言处理社区,受众覆盖国内外NLP硕博生、高校老师以及企业研究人员。
转载自 | DataWhale
编辑 | 极市平台
作者丨张帆,陈安东
引言
Llama进化史(第1节) 模型架构(第2节) 训练数据(第3节) 训练方法(第4节) 效果对比(第5节) 社区生态(第6节) 总结(第7节)
1. Llama进化史
1.1 Llama-1 系列
1.2 Llama-2 系列
1.3 Llama-3
2. 模型架构
为了增强训练稳定性,采用前置的RMSNorm [6]作为层归一化方法。 为了提高模型性能,采用SwiGLU [7]作为激活函数。 为了更好地建模长序列数据,采用RoPE [8]作为位置编码。 为了平衡效率和性能,部分模型采用了分组查询注意力机制(Grouped-Query Attention, GQA)[9]。
2.1 Llama-1 系列
2.2 Llama-2 系列
2.3 Llama-3 系列
3. 训练数据
3.1 Llama-1 系列
英语CommonCrawl:Llama-1预处理了2017年至2020年间的五个CommonCrawl数据集。该过程在行级别去重,使用fastText线性分类器进行语言识别以去除非英语页面,并使用n-gram语言模型过滤低质量内容。此外,Llama-1训练了一个线性模型来分类维基百科中用作参考的页面和随机采样的页面,并丢弃了未被分类为参考的页面。 C4:在探索性实验中,Llama-1观察到使用多样化的预处理CommonCrawl数据集可以提升性能。因此,Llama-1的数据中包括了公开可获得的C4数据集。C4的预处理也包括去重和语言识别步骤:与CCNet的主要区别在于质量过滤,主要依赖于标点符号的存在或网页中的单词和句子数量等启发式规则。 Github:Llama-1使用Google BigQuery上可公开获取的GitHub数据集。Llama-1仅保留在Apache、BSD和MIT许可下分发的项目。此外,Llama-1还使用基于行长度或字母数字字符比例的启发式规则过滤低质量文件,并用正则表达式移除如页眉等样板内容。最后,Llama-1在文件级别对结果数据集进行去重,匹配精确相同的内容。 维基百科:Llama-1添加了2022年6月至8月期间的维基百科数据,涵盖使用拉丁或西里尔文字的20种语言。Llama-1处理数据以移除超链接、评论和其他格式化的样板内容。 Gutenberg和Books3:Llama-1在训练数据集中包括了两个书籍语料库:Gutenberg项目(包含公共领域的书籍)和ThePile的Books3部分,一个公开可获得的用于训练大型语言模型的数据集。Llama-1在书籍级别进行去重,移除超过90%内容重合的书籍。 ArXiv :Llama-1处理ArXiv的Latex文件,以增加科学数据到Llama-1的数据集。Llama-1移除了第一节之前的所有内容以及参考文献部分。Llama-1还移除了.tex文件中的注释,并内联扩展了用户编写的定义和宏,以增强论文间的一致性。 Stack Exchange:Llama-1包括了Stack Exchange的数据转储,这是一个涵盖从计算机科学到化学等多种领域的高质量问题和答案的网站。Llama-1保留了28个最大网站的数据,移除了文本中的HTML标签,并根据得分将答案排序(从最高到最低)。
3.2 Llama-2
我们将继续努力微调模型,以提高在其他语言环境下的适用性,并在未来发布更新版本,以解决这一问题。
3.3 Llama-3 系列
4. 训练方法
4.1 Llama-1系列
4.2 Llama-2系列
4.3 Llama-3系列
5. 效果对比
5.1 Llama-2 vs Llama-1
5.2 Llama-3 vs Llama-2
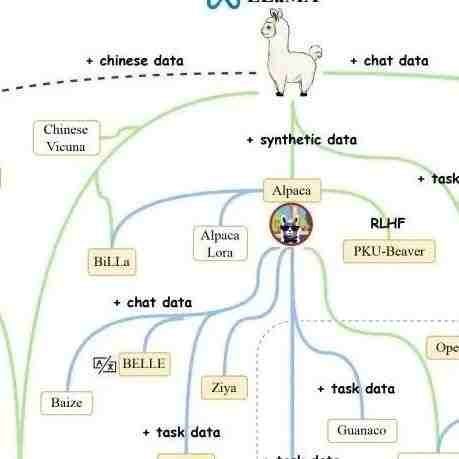
6. 社区影响
6.1 开放源代码模型的力量
6.2 对全球AI研发的影响
6.3 技术进步和社区创新
6.4 生态系统和多样性
6.5 Llama社区的未来展望
7. 总结
扫描二维码添加小助手微信
关于我们
关键词
模型
大模型
性能
预训练
数据集
最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。