Meta联合纽约大学和华盛顿大学提出MetaCLIP,带你揭开CLIP的高质量数据之谜
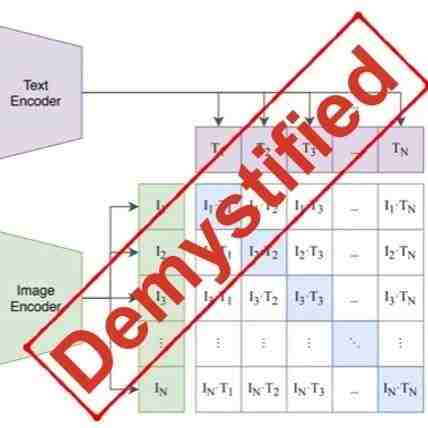
自 2021 年诞生,CLIP 已在计算机视觉识别系统和生成模型上得到了广泛的应用和巨大的成功。我们相信 CLIP 的创新和成功来自其高质量数据(WIT400M),而非模型或者损失函数本身。虽然 3 年来 CLIP 有大量的后续研究,但并未有研究通过对 CLIP 进行严格的消融实验来了解数据、模型和训练的关系。
CLIP 原文仅有简短的数据处理描述,而后续工作依靠已经训练好的 CLIP 来重新过滤数据去训练 CLIP(学生)模型。更广泛地说,虽然目前的开源着重强调已训练模型权重的公开,而训练数据以及如何从低质量数据获得高质量数据的技巧的公开度却往往并不那么高。
本文带你揭开 CLIP 的数据质量之谜,为开源社区带来元数据导向的 CLIP 预训练(MetaCLIP)。
论文标题:
Demystifying CLIP Data
论文链接:
https://arxiv.org/abs/2309.16671
代码链接:
https://github.com/facebookresearch/MetaCLIP
MetaCLIP数据质量
MetaCLIP 根据 CLIP 原文对数据处理的描述,提出可扩展到整个 CommonCrawl 上的数据算法。该算法接受原始互联网数据分布,产生在元数据上平衡的高质量训练数据分布。
MetaCLIP 产生的数据质量源自两个部分:
(1) 通过元数据字符串匹配来抓取高质量人类监督文本;
(2)通过平衡数据在元数据上的分布来最大限度保留长尾数据的信号、弱化噪声以及头部分布的冗余信息。MetaCLIP 的元数据来自 50 万个 WordNet 和维基百科的视觉概念(visual concept),它们使被匹配的 alt 文本包含超越人类平均认知水平的监督质量(superhuman level supervision)。
我们的实验严格遵循 CLIP 设定来控制研究数据分布对结果的影响。整个数据提取,训练无需已训练 CLIP 来过滤数据以及潜在未知的来自 OpenAI CLIP 的数据偏见。
相反的是,MetaCLIP 数据算法同时输出训练数据分布。这使得训练数据更加透明,以方便调试模型。MetaCLIP 在 400M 训练数据上达到 ViT-B 70.8% 的零样本 ImageNet 分类精度;使用 1B 训练数据上达到 72.4%;在 2.5B 训练数据上使用 ViT-bigG 模型达到 82.1%,而整个模型和训练参数并未进行任何更改(比如学习率或批样本量)。
消融实验表明:字符串匹配(MetaCLIP w/o bal. (400M))和平衡分布(MetaCLIP(400M)) 对 MetaCLIP 的数据质量产生重大贡献。
CLIP数据算法介绍
本文正式提出 CLIP 数据算法,来简化和产生高质量的训练数据。
该方法大致分为:创建元数据,提出数据算法,提高数据质量及输出训练数据等四个步骤。
具体方法见下:
(1) 实现了 CLIP 数据的相关描述,包括如何创建元数据;
(2)提出如下数据算法:第一部分为元数据字符串匹配,第二部分为平衡数据分布。该算法简洁可扩展,本文已证明可在所有 CommonCrawl 300+B 级图片样本并行运行;
(3)可植入已有数据流水线或者数据加载器(data loader)来提高数据质量;
(4)输出训练数据在元数据上的训练分布使得训练数据更透明。
该算法的 python 代码如下:
MetaCLIP 的元数据来自 WordNet 和 Wikipedia 的高质量视觉概念(visual concept)。我们根据 CLIP 原文描述实现了从维基百科提取 uni/bi-gram 以及高频标题的过程。
相关选取的超参数如下:
▲ 元数据的创建来源
MetaCLIP 算法简洁,可以将两部分分开植入已有的数据流水线。
如下图所示,该算法可以在数据流水线的早期进行植入,来减小数据规模和对计算资源存储的开销:
- 第一部分(元数据字符串匹配)能减少 50% 的数据量;
第二部分(平衡数据分布)能减少 77% 的数据量。
▲ 算法可轻松接入已有数据流水线,降低处理低质量数据的开销
下图展示了平衡数据分布的效果:横坐标将元数据里每个视觉概念的匹配数量从低到高排列,纵坐标累计匹配。
表格中展示了不同频率区段视觉概念的匹配数量:
▲ 平衡数据分布使得1.6B的原始数据被下采样成400M的训练数据
我们可以看到 MetaCLIP 数据算法对头部分布进行了高度下采样,这将降低头部分布的冗余无效信息和头部数据的噪声(比如 untitled photo),所有长尾分布的视觉概念全部保留。
实验结果
我们设计了两个数据池来运行数据算法。
- 第一个池的目标是获得 400M 训练数据来和 CLIP 进行比较;
- 第二个池的目标是所有 CommonCrawl 数据。
我们进一步对第二个数据池运行了两次数据算法,一次设定头尾分布的阈值(t=20k)与 400M 一致(最终获得 1B 数据),一次设定尾部分布的比例与 400M 尾部的比例一致(t=170k,最终获得 2.5B 数据)。
MetaCLIP 在 DataComp 的 38 个任务上的实验结果如下:
我们可以看到 MetaCLIP 在 400M 上略好于 OpenAI CLIP 或者 OpenCLIP。在第二个池上性能进一步超越 400M。更多的数据在更大的模型 ViT-bigG 上产生更好的效果。而这些性能的提升完全来自数据而非模型结构改进或者训练技巧本身。
在 CLIP/SLIP 每个分类任务上的详细实验结果请参考原文。
实验结论
本文提出了 CLIP 的数据算法来产生高质量训练数据:算法可在所有 CommonCrawl 的 300+B 级图片样本对上并行运行。
实验表明元数据字符串匹配和平衡分布都对结果有重大贡献,算法无需使用 CLIP 模型过滤或者提高训练开销来提升性能,并且使得训练数据分布更加透明。
更多阅读
#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:[email protected]
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿
△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。